
콘텐츠

Arm은 새로운 Mali-G77 그래픽 프로세서 및 Mali-D77 디스플레이 프로세서와 함께 최신 고성능 CPU 설계 인 Cortex-A77을 발표했습니다. 작년의 Cortex-A76과 마찬가지로 Cortex-A77은 Arm의 고유 한 저전력 소비를 요구하는 프리미엄 계층 애플리케이션을 위해 설계되었습니다. 스마트 폰에서 랩톱에 이르기까지 모든 것을 포함합니다.
Cortex-A77을 통해 Arm은 Cortex-A76을 통해 관리 할 수있는 최대 사이클 당 클럭 명령 (IPC) 성능 향상을 목표로 삼았습니다. 클록 주파수, 전력 소비 및 면적은 모두 거의 동일한 구장에 유지되도록 설계되었지만 새로운 코어는 한 번에 더 많은 명령을 수행 할 수 있습니다. 이를 위해 Arm은 작년보다 훨씬 넓은 코어를 설계했으며 CPU 코어에 할 일을 계속 공급하기 위해 여러 가지 개선 작업을 수행했습니다. 그러나 그에 도달하기 전에 높은 수준의 개요 및 성능 수치를 살펴 보겠습니다.
타격 성과 목표
2018 년 8 월 Arm은 2020 년까지 CPU 로드맵을 특징없이 공유했습니다. 2016 년 Cortex-A73에서 2020 년의 "Hercules"설계에 이르기까지이 회사는 컴퓨팅 성능이 2.5 배 향상 될 것으로 약속했습니다. Cortex-A76을 사용한 주요 마이크로 아키텍처 시프트, 더 높은 최신 클럭 속도, 그리고 16nm에서 10으로, 현재는 5nm에서 7nm로 이동하면서이 거대한 프로젝션의 상당 부분이 달성되었습니다. 작년까지 약 1.8 배의 로드맵 이익이 이미 달성되었으며 Cortex-A77은 약 20 % 더 IPC 향상을 제공합니다. 전력 및 열 예산이 제한된 모바일 장치가 이러한 이점을 모두 기대하지는 않지만 Arm의 2.5 배 목표를 달성 할 수 있습니다.
비교를 위해 작년 Cortex-A76은 Cortex-A75보다 약 30-35 % 향상되었습니다. 올해 우리는 A77과 A76 사이에서 20 %의 IPC 이득이 더 음소거되었지만 여전히 유의미한 것으로보고 있습니다. 이것은 이전과 비슷한 열 및 전력 제약 조건을 고수하면서 더 많은 성능을 의미하기 때문에 좋은 소식입니다. 단점은 A77이 A76보다 약 17 % 더 크기 때문에 실리콘 면적 측면에서 약간 더 비싸다는 것입니다. 데스크탑 리더와의 비교를 원한다면 AMD는 Zen2와 Zen + 사이에서 15 %의 IPC 향상을 관리했으며 인텔의 IPC는 몇 년 동안 거의 정적으로 유지되었습니다.물론 우리는 여기서 다른 시장 부문에 대해 이야기하고 있지만, 이것은 팔의 CPU 디자인 팀이 최근 세대에서 어떻게 인상적인 이익을 얻었는지를 보여줍니다.
차세대 Cortex-A77 기반 SoC에 20 % 성능 향상 제공
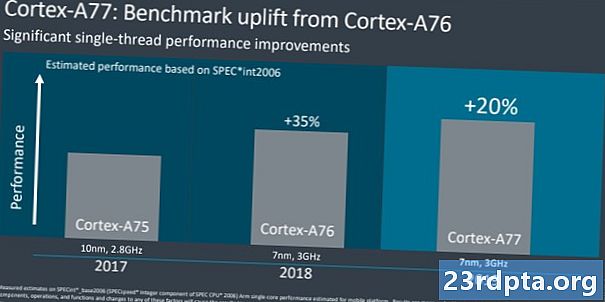
여기서 A76은 A77을 통해 최적화 수준 향상으로 되돌아가는 반면, A76은 성능이 크게 향상되어 주요한 마이크로 아키텍처 전환을 기록했습니다. 이를 중단하고 Arm Cortex-A77의 새로운 기능을 살펴 보겠습니다.
Cortex-A77은 A76 마이크로 아키텍처를 기반으로합니다.
Cortex-A77과 A76의 차이점을 이해하는 핵심은“더 넓은”코어 설계의 의미를 파악하는 것입니다. 본질적으로, 우리는 각 클럭 사이클에 대해 더 많은 명령어를 실행하는 능력에 대해 이야기하고 있으며, 이는 코어의 처리량을 증가시킵니다. 이 권한을 얻는 데 중요한 두 가지 부분이 있습니다. 처리를 수행 할 실행 장치 수를 늘리고 이러한 장치에 데이터가 잘 공급되도록하는 것입니다. 후자부터 시작하여 SoC의 디스패치, 캐시 및 분기 예측기 부분에 중점을 둡니다.
Cortex-A77은 A76을 사용하여 4 개에서주기 당 최대 6 개의 명령어로 디스패치 폭을 50 % 향상시킵니다. 이는 더 큰 성능 잠재력을 위해 각 클럭주기마다 실행 코어로 향하는 더 많은 명령어를 의미합니다. 결과적으로 비 순차적 실행 창이 더 커져 더 많은 병렬 처리를 제공하기 위해 160 개의 항목으로 증가합니다. 64K 명령어 캐시는 친숙한 반면, 분기 예측기의 주소를 보유하는 BBT (Branch Target Buffer)는 병렬 명령어의 증가를 처리하기 위해 이전보다 33 % 더 큽니다. 여기서 특별한 점은 없으며, 작년 디자인의 기본 버전보다 더 넓습니다.
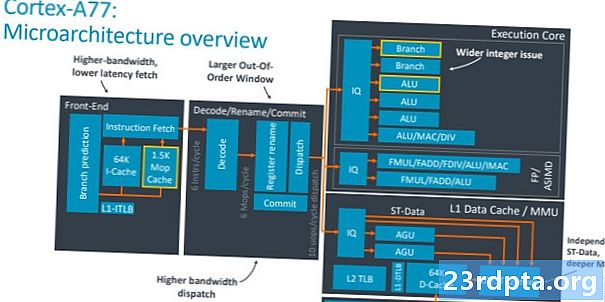
보다 흥미로운 프론트 엔드 추가 기능은 완전히 새로운 1.5K MOP 캐시이며,이 장치는 디코드 장치에서 피드백되는 매크로 연산 (MOP)을 저장합니다. Arm의 CPU 아키텍처는 사용자 응용 프로그램의 명령을 더 작은 매크로 작업으로 해독 한 다음 실행 코어가 이해하는 마이크로 연산으로 내려갑니다. 디코드 섹션의 위 다이어그램에서이를 확인할 수 있습니다. MOP 캐시는 누락 된 브랜치 및 플러시의 비용 페널티를 줄이기 위해 사용됩니다. 매크로-옵스를 다시 디코딩하지 않고 계속 잡고 코어의 전체 처리량을 증가시킵니다. i- 캐시가 아닌 MOP에서 페치하면 디코드 단계를 우회하여 한주기를 절약 할 수 있습니다. Arm은 MOP 캐시가 다양한 워크로드에서 85 % 이상의 적중률에 도달 할 수 있으며 표준 i- 캐시에 매우 유용하게 사용할 수 있다고 말합니다.
CPU의 실행 코어 부분으로 이동하면서 네 번째 ALU와 두 번째 분기 장치가 추가되었습니다. 이 네 번째 ALU는 프로세서의 일반 수 크 런칭 대역폭을 50 % 향상시킵니다. 이 추가 ALU는 기본 1 사이클 명령 (예 : ADD 및 SUB)과 곱셈과 같은 2 사이클 정수 연산이 가능합니다. 다른 ALU 중 2 개는 기본 1 사이클 명령 만 처리 할 수있는 반면 최종 장치에는 나누기, 곱하기 누적 등과 같은 고급 수학 연산이 청구됩니다. 실행 코어 내부의 두 번째 분기 장치는 동시 분기 점프 수를 두 배로 늘립니다. 코어는 처리 할 수 있는데, 이는 6 개의 디스패치 된 명령 중 2 개가 분기 점프 인 경우에 유용합니다. 조금 이상하게 들리지만 Arm의 내부 테스트 결과이 두 번째 유닛을 채택하면 성능상의 이점이 발견되었습니다.
Cortex-A77은 향상된 병렬 처리 기능과 프리 페치 캐시의 새로운 테이크를 제공합니다
CPU 코어에 대한 다른 조정에는 두 번째 AES 암호화 파이프 라인 추가가 포함됩니다. 데이터 저장소 파이프 라인에는 메모리 발급 대역폭을 두 배로 늘리기위한 전용 발급 포트가 있습니다. 이 포트는 이전에 ALU와 공유되어 병목 현상이 발생할 수 있습니다. 또한 전력 효율을 향상시키는 동시에 시스템 DRAM의 대역폭을 증가시키는 차세대 데이터 완벽 함이 있습니다.
Cortex-A77에서이 시스템의 일부에는 완전히 새로운 "시스템 인식"프리 페치 시스템도 있습니다. 이를 통해 광범위한 CPU 코어 수, 캐시 용량 및 대기 시간, 최종 장치 내부의 메모리 하위 시스템 구성을 기반으로 메모리 성능이 향상됩니다. DynamIQ CPU 클러스터의 일부로 DSU (Dynamic Scheduling Unit)와 통신하기위한 전용 하드웨어로, 공유 L3 캐시의 사용량을 모니터링합니다. 코어에는 동적 거리 및 공격성 수준이있어 L3 대역폭이 다른 CPU 코어에 의해 제한되는 상황에서 캐시 사용률을 줄입니다. Cortex-A77과 같은 고성능 코어는 메모리에 대한 DSU 액세스를 포화시킬 가능성이 높지만 A55와 같은 저전력 코어는 그럴 가능성이 낮습니다.

모두 함께 맞추기
Cortex-A77에는 이전 모델과 실질적인 차이를 더하는 작은 변경 사항이 많이 있습니다. 간단히 말해서, A77s의 새로운 MOP 캐시는 더 넓고 더 긴 명령 창과 결합되어 강화 된 ALU, 브랜치 및 메모리 장치가해야 할 일을 바쁘게 유지하는 데 도움이됩니다. 강력한 Cortex-A76 설계는 더 높은 클럭 속도에 의존하지 않고 A77을 통해 처리량을 더욱 향상시키기 위해 확장되었습니다.
Cortex-A77의 최대 성능 향상은 정수 및 부동 소수점 수학 형식으로 나타납니다. 이는 SPEC 정수 및 부동 소수점 벤치 마크에서 각각 20 ~ 35 %의 성능 향상을 보여주는 Arm의 내부 벤치 마크에 의해 확인됩니다. 메모리 대역폭 개선은 15 ~ 20 % 정도에 달하며, 최대의 이득은 숫자 크 런칭의 형태로 나타납니다. 전반적으로 이러한 개선으로 A77은 이전 세대에 비해 평균 20 % 향상되었습니다. 또한 올해 말이나 2020 년 초에 고급 7nm 제조 공정의 결과로 더 많은 한계가 생길 수 있습니다.
스마트 폰 측면에서 Cortex-A77 기반 SoC는 고성능 플래그십 제품을 대상으로합니다. Arm은 강력한 설계로 4 + 4 비트를 사용할 것으로 기대하고있다. 처리량 증가와 A77의 면적 크기에 약간의 영향이 주어지면 SoC 설계자는 1 + 3 + 4 또는 2 + 2 + 4 추세를 계속 유지할 것입니다. 더 큰 캐시와 더 높은 클럭을 가진 하나 또는 두 개의 강력한 큰 코어를 사용하면 더 작은 캐시 크기와 더 낮은 클럭을 가진 2 개 또는 3 개의 A77 코어로 백업되어 전력 및 면적을 절약합니다. 궁극적으로 Cortex-A77은 스마트 폰 칩의 장점과 항상 연결된 Arm 기반 랩톱의 시장 성장에 도움이됩니다. 올해 말 실리콘 발표에 주목하십시오.


